Deploying Tanzu for vSphere with NSX-T
First in a series of posts which build on each other looking Tanzu.
- Deploying Tanzu for vSphere with NSX-T
- Managing Tanzu for vSphere Clusters Using ClusterAPI
- Managing Tanzu for vSphere Clusters Using Tanzu Misson Control
- Deploying Tanzu for AWS Using Tanzu Misson Control
Supervisor Cluster Bootstrap
The enablement of Workload Control Plane triggers the deployment of three VMs which initially have single vNIC eth0 connected to a PortGroup which can route to vCenter and NSX. This appears to configure the first VM as bootstrap Kubernetes Node on which are deployed multiple Pods. The NSX Container Plug-in (NCP) Pod performs integration of Kubernetes and NSX-T.
kubectl get pods -n vmware-system-nsx
NAME READY STATUS RESTARTS AGE
nsx-ncp-7c6578d9fd-xj6jk 1/1 Running 3 25h
During the bootstrap of the Supervisor Cluster the requires NSX objects are created by the NCP Pod. The NCP Pod is configured with a ConfigMap which includes details of how to connect to the NSX API.
```bash
kubectl get pods -A | grep ncp
vmware-system-nsx nsx-ncp-7c6578d9fd-xdqvl 1/1 Running 6 2d22h
kubectl describe pod nsx-ncp-7c6578d9fd-xdqvl -n vmware-system-nsx | grep config
ConfigMapName: nsx-ncp-config
kubectl describe ConfigMap nsx-ncp-config -n vmware-system-nsx | grep manager
nsx_api_managers = 192.168.10.28:443
Routing Domains
The Workload Control Plane configures various components on discreet network segments. The Management, Ingress and Egress networks all need to be part of a common routing. In this deployment the Managemenet network operates within a VLAN defined on the physical network. The Workload Control Plane deployment creates the Ingress and Egress networks as NSX-T logical segments. To faciliate the correct sharing of routes the NSX-T Tier-0 router is configured as a BGP Autonomous System which peers with the physical router, both advertise and share routes.
No-NAT Topology
It is possible [from vCenter Server 7.0 Update 3] to deploy a No-NAT (routed) topology which allows routing outside of the cluster network, more info on No-NAT here.
NAT Topology
In this deployment I deployed the default NAT (routed) topology where the Kubernetes POD and Service are within the same routing domain. Communications to the wider network is facilitated by combination of NAT, Load Balancer Ingress and Egress.
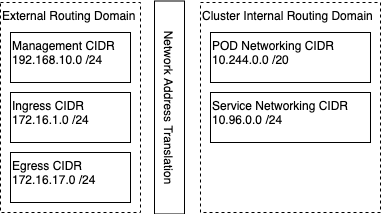
A NSX-T logical segment is created for ther Kubernetes Cluster network ( 10.244.0.0 /20 ) which all the Nodes and Pods will attach.
NSX-T Service Load Balancers get created which correspond to the Ingress resources:
| Pod | Ingress IP Allocation | Port | Protocol |
|---|---|---|---|
| vsphere-csi-controller | 172.16.1.1 | 2112 | L4 TCP |
| vsphere-csi-controller | 172.16.1.1 | 2113 | L4 TCP |
| kube-apiserver | 172.16.1.2 | 6443 | L4 TCP |
| kube-apiserver | 172.16.1.2 | 443 | L4 TCP |
NSX-T Distributed Load Balancers get created which correspond to the ClusterIP service resources:
| Pod | Ingress IP Allocation | Port | Protocol |
|---|---|---|---|
| kubernetes | 10.96.0.1 | 443 | L4 TCP |
| kube-dns | 10.96.0.10 | 53 | L4 TCP |
| kube-dns | 10.96.0.10 | 53 | L4 UDP |
| kube-dns | 10.96.0.10 | 9153 | L4 TCP |
| tkg-vmware-system-tkg-webhook-service | 10.96.0.57 | 443 | L4 TCP |
| vmop-webhook-service | 10.96.0.70 | 443 | L4 TCP |
| capw-capw-controller-manager-metrics-service | 10.96.0.72 | 9846 | L4 TCP |
| capw-capw-controller-webhook-service | 10.96.0.168 | 443 | L4 TCP |
| kube-apiserver-lb-svc | 10.96.0.186 | 443 | L4 TCP |
| kube-apiserver-lb-svc | 10.96.0.186 | 6443 | L4 TCP |
| tkg-vmware-system-tkg-controller-manager-metrics-service | 10.96.0.202 | 9847 | L4 TCP |
| vmop-controller-manager-metrics-service | 10.96.0.204 | 9848 | L4 TCP |
| capw-capi-kubeadm-bootstrap-webhook-service | 10.96.1.44 | 443 | L4 TCP |
| capw-capi-controller-manager-metrics-service | 10.96.1.45 | 9844 | L4 TCP |
| nsop-vmware-system-nsop-webhook-service | 10.96.1.87 | 443 | L4 TCP |
| capw-capi-kubeadm-control-plane-controller-manager-metrics-service | 10.96.1.95 | 9848 | L4 TCP |
| vmware-system-license-operator-webhook-service | 10.96.1.112 | 443 | L4 TCP |
| capw-capi-kubeadm-bootstrap-controller-manager-metrics-service | 10.96.1.136 | 9845 | L4 TCP |
| cert-manager-cert-manager | 10.96.1.149 | 9402 | L4 TCP |
| psp-operator-webhook-service | 10.96.1.150 | 443 | L4 TCP |
| capw-capi-webhook-service | 10.96.1.163 | 443 | L4 TCP |
| docker-registry | 10.96.1.170 | 5000 | L4 TCP |
| apiserver-authproxy | 10.96.1.173 | 8443 | L4 TCP |
| csi-vsphere-csi-controller | 10.96.1.208 | 2112 | L4 TCP |
| csi-vsphere-csi-controller | 10.96.1.208 | 2113 | L4 TCP |
| capw-capi-kubeadm-control-plane-webhook-service | 10.96.0.235 | 443 | L4 TCP |
| tkg-tkgs-plugin-service | 10.96.1.245 | 8099 | L4 TCP |
| cert-manager-cert-manager-webhook | 10.96.1.252 | 443 | L4 TCP |
The following three NAT rules are put in place to facilitate Egress with NSX-T:
| Action | Source | Destination | Translation |
|---|---|---|---|
| SNAT | Any | Any | 172.16.2.1 |
| No SNAT | 10.244.0.0/20 | 10.244.0.0/20 | Any |
| No SNAT | 10.244.0.0/20 | 172.16.2.0/24 | Any |
Supervisor Cluster DNS Complexities
At this stage the VMs have a single NIC eth0 and management DNS resolver.
Once the NCP has created the required NSX objects the bootstrap node has a 2nd NIC added eth1 which is connected to the Cluster Network segment. This enables configuration to proceed on the bootstrap host after which the 2nd and 3rd Nodes are configured and have 2nd NIC added onnected to the Cluster Network segment.
I initially had issue where the installation status got stuck in “configuring” state. When I SSH to the first control plane VM I saw various error messages with various components. For example authorization errors were due to the kube-apiserver not being able to resolve the vCenter’s fqdn for SSO. I had the NCP Pod moving to CrashLoopBackoff status again with what looked like fqdn lookup issues. This was confusing as during the earlier stages of the bootstrap process the bootstrap node had connected to vCenter and NSX using Management DNS resolver.
When working through the WCP installation UI there are two places to enter DNS server IP address. The first is a DNS resolver with A and PTR records for the management components. The Kubernetes CoreDNS performs lookups between Pods and Services within the Cluster. The second DNS entry what CoreDNS falls back to for FQDN lookups external of the Cluster. In my environment I have a single DNS solution which hosts both management and workload zones so the IP address (192.168.10.10) is common.
When I connect to first control plane VM I noticed I could ping DNS server via its management interface but could not ping DNS via workload interface.
ifconfig
eth0 Link encap:Ethernet HWaddr 00:50:56:b3:29:f3
inet addr:192.168.10.45 Bcast:192.168.10.255 Mask:255.255.255.0
...
eth1 Link encap:Ethernet HWaddr 04:50:56:00:d0:00
inet addr:10.244.0.2 Bcast:10.244.0.15 Mask:255.255.255.240
...
ping 192.168.10.10 -I eth0 -c 1
PING 192.168.10.10 (192.168.10.10) from 192.168.10.45 eth0: 56(84) bytes of data.
64 bytes from 192.168.10.10: icmp_seq=1 ttl=128 time=0.412 ms
--- 192.168.10.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.412/0.412/0.412/0.000 ms
ping 192.168.10.10 -I eth1 -c 1
PING 192.168.10.10 (192.168.10.10) from 10.244.0.2 eth1: 56(84) bytes of data.
From 10.244.0.1 icmp_seq=1 Destination Host Unreachable
--- 192.168.10.10 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
So here I know I have a routing or Egress issue from workload to management routing domain. I would expect however the VM should still resolve vCenter and NSX-T records on management DNS and bootstrapping should comlete. I checked the network config to ensure that eth0 had correct DNS server IP and the routing table appeared correct.
cat /etc/systemd/network/10-eth0.network | grep DNS
DNS = 192.168.10.10
cat /etc/systemd/network/10-eth1.network | grep DNS
DNS = 10.244.0.2
route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.10.254 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.240 U 0 0 0 eth1
192.168.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
Looking deeper at routing policy redirects traffic to 192.168.10.10 via eth1. As we know routing from eth1 was to DNS was not possible this causes the DNS issue.
ip rule show
0: from all lookup local
0: from all to 192.168.10.10 lookup 200
0: from all to 172.16.1.0 /24 lookup 200
0: from all to 10.244.0.0 /20 lookup 200
0: from 10.244.0.2 lookup 200
0: from all to 100.64.0.0 /16 lookup 200
0: from all to 10.96.0.0 /23 lookup 200
32766: from all lookup main
32767: from all lookup default
ip route show table 200
default via 10.244.0.1 dev eth1 proto static
10.244.0.0/28 dev eth1 proto static scope link
Interestingly if I remove Workload Management and then redeploy specifing Management DNS 192.168.10.10 but chaning Workload DNS to alternate IP but still on unroutable address 192.168.10.11. The deployment does not get stuck at the same place and completes successfully. Looking at routing policy having unique DNS IP addressing does not force traffic to 192.168.10.10 via eth1.
ip rule show
0: from all lookup local
0: from all to 172.16.1.0 /24 lookup 200
0: from all to 10.244.0.0 /20 lookup 200
0: from all to 10.96.0.0 /23 lookup 200
0: from 10.244.0.2 lookup 200
0: from all to 100.64.0.0 /16 lookup 200
0: from all to 192.168.10.11 lookup 200
32766: from all lookup main
32767: from all lookup default
ip route show table 200
default via 10.244.0.1 dev eth1 proto static
10.244.0.0/28 dev eth1 proto static scope link
Workload Cluster DNS Traffic
While useful to understand if the workloa cluster CoreDNS cannot route to the configured upstream DNS server it will cause an issue later so the unerlying cause needs resolving. For me the issue was the DNS server was dual homed and required static route adding for 172.16.0.0/16 to redirect to the router which was BGP peered to the NSX Edge.
Kubectl vSphere Login Traffic
To connect to the Supervisor Cluster we connect to the LoadBalancer VIP representation of Kubernetes API ( 172.16.1.2 ).
set KUBECTL_VSPHERE_PASSWORD={my password}
kubectl vsphere login --server=172.16.1.2 --vsphere-username administrator@vsphere.local --insecure-skip-tls-verify --verbose 10
kubectl config use-context 172.16.1.2